Page Notation in the library's documentation summarises some of the notation used here and throughout the entire library.
Graph Theory
Node / Vertex
A node of a graph is represented throughout the entire library with the type lal::node. Such type is just an integer, an index of a node. Such index ranges in \([0,n-1]\). Moreover, those functions that return a node, will always return a value greater than or equal to \(n\) in case that such node could not be found.
We typically use letters \(s,t,u,v\) to denote nodes. Letter \(r\) is also used but is often reserved for the root of a rooted tree.
Readers might find the noun vertex used instead of node. These two words then are synonyms.
Edge
An edge of a graph is simply a pair of vertices. Recall vertices are usually implemented using integer values; these are simply values from \(0\) to \(n-1\), where \(n\) denotes the number of vertices of the graph. An edge is represented with the type lal::edge.
Pair of independent/disjoint edges
A pair of independent/disjoint edges \(e_1,e_2\) are two edges that do not share vertices. In other words, if \(e_1=\{s,t\}\) and \(e_2=\{u,v\}\) are independent then the vertices \(s,t,u,v\) are pairwise distinct. An pair of edges (not necessarily independent/disjoint) is represented with the type lal::edge_pair.
Linear Arrangement
A linear arrangement is a well-known concept that relates vertices to distinct positions in a linear ordering. Linear arrangements are often denoted with \(\pi\) in the literature; in this library we also follow this notation. Moreover, in this library linear arrangements are implemented with two arrays describing said relationship. One array gives the values \(\pi(u)\), which is the position of vertex \(u\) in the linear arrangement; the other array gives the values \(\pi^{-1}(p)\), which is the vertex at position \(p\) in the linear arrangement.
In the mathematical sense, a linear arrangement is a permutation, a bijective function \(\pi \;:\; V \longrightarrow [0,n-1]\), for which:
- \(\pi(u)=p\) when the position of vertex \(u\) is \(p\).
- \(\pi^{-1}(p)=u\) when at position \(p\) we find vertex \(u\).
See the figure below for an illustration of a linear arrangement.
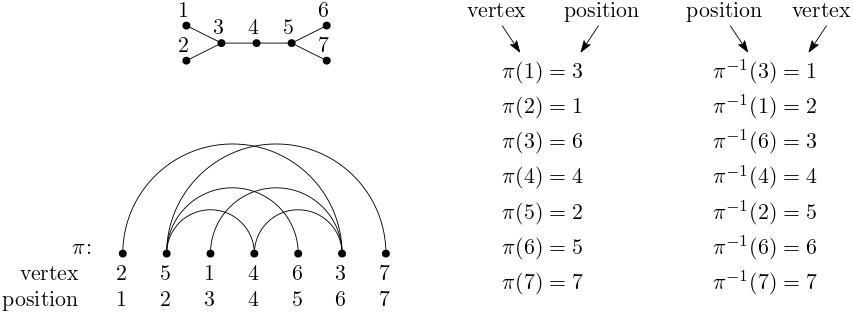
The two arrays underlying a linear arrangement describe the function \(\pi\). One array gives the values \(\pi(u)\) (lal::linear_arrangement::m_direct); the other array gives the values \(\pi^{-1}(p)\) (lal::linear_arrangement::m_inverse).
In code, if arr is a linear arrangement of n nodes:
An arrangement can be queried for its contents in two ways.
- The vertex at position p can be retrieved using:
- The position of vertex u can be retrieved using:
In C++ this can be done more easily and more comfortably via the "[]" operator. The examples above can be simplified to
- Querying the position of a vertex
- Querying the vertex at a position
Identity Linear Arrangement
For the sake of simplicity in documenting this library, we define the identity arrangement \(\pi_I\) as the arrangement that maps each node into the position corresponding to their label. More formally, \(\pi_I(u_i)=i\), where \(u_i\) denotes the \(i\)-th vertex in the graph. This is a special case of linear arrangement used in many functions in this library and is dealt with internally. In order to provide an identity arrangement to a function, users only need to provide an empty arrangement.
However, an empty arrangement cannot be used (by the user) as shown in the examples above. In order to create an identity arrangement usable by the user, do
Properties that can be defined in linear arrangements
Many properties can be defined in a linear arrangement of a graph \(G\). LAL users need to know the following.
- Edge crossings: two edges \(uv\) and \(st\) cross in a linear arrangement \(\pi\) if \(\pi(u) < \pi(s) < \pi(v) < \pi(t)\) or \(\pi(s) < \pi(u) < \pi(t) < \pi(v)\) when assuming, without loss of generality, that \(\pi(u)<\pi(v)\) and \(\pi(s)<\pi(t)\).
- Edge lengths: the length of an edge \(uv\) in a linear arrangement \(\pi\) is defined as \(d_{\pi}(uv)=|\pi(u) - \pi(v)|\).
- Vertex covering: a vertex \(u\) is covered by an edge \(st\) when \(\pi(s)<\pi(u)<\pi(t)\) or \(\pi(t)<\pi(u)<\pi(s)\)
A usage example
Now follows two examples on how to calculate the number of edge crossings in a linear arrangement and how to do so using an identity arrangement.
Types of arrangements
There are many types of arrangements used in this library. For example, some functions return an arrangement of the types described below, some classes enumerate all arrangements of these types given an input tree.
- Planar arrangements of a graph: A planar arrangement of a graph is an arrangement in which there are no edge crossings. It does not matter if the graph is a free tree, rooted tree, or otherwise.
- Projective arrangements of a rooted tree: A projective arrangement of a rooted graph is an arrangement in which there are no edge crossings and the root vertex of the graph is not covered by any edge. Then, a projective arrangement is also a planar arrangement and the root vertex cannot be covered. Notice that the graph must be rooted, so a tree must be rooted to have a projective arrangement.
- Bipartite arrangements of a bipartite graph: a bipartite arrangement of a bipartite graph \(B = (V_1\cup V_2, E)\) is an arrangement where the first vertices in the arrangement are those from \(V_1\) followed by those from \(V_2\) (or viceversa) [7].
There are no types for these arrangements.
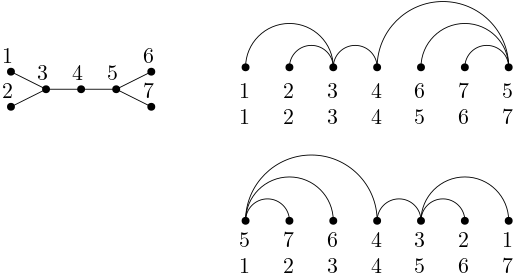
Mirroring an arrangement
An arrangement \(\pi\) can be mirrored, denoted with \(\tilde{\pi}\) in that we can revert the sequence of vertices in the linear ordering.
Level sequence of an arrangement
We define the level sequence \(L_\pi(G)\) of an arrangement \(\pi\) of a graph \(G\) [18] [39] [7] as the sequence of level values of the vertices of \(G\) in \(\pi\). The level value of a vertex \(u\), denoted as \(l_\pi(u)\) is simply the difference between the number of its neighbours to its right in the arrangement, \(r_\pi(u)\), and the number of its neighbours to its left in the arrangement, \(l_\pi(u)\).
- \(\mathfrak{r}_\pi(u) := |\{ v\in\Gamma(u) \;|\; \pi(u)<\pi(v) \}|\)
- \(\mathfrak{l}_\pi(u) := |\{ v\in\Gamma(u) \;|\; \pi(v)<\pi(u) \}|\)
- \(l_\pi(u) := \mathfrak{r}_\pi(u) - \mathfrak{l}_\pi(u)\)
Then, \(L_\pi(G) := (l_\pi(u_1), \dots, l_\pi(u_n))\), where \(u_i\) denotes the vertex at position \(i\) in \(\pi\).
Arrangement isomorphism
Two arrangements \(\pi_1\) and \(\pi_2\) of the same graph \(G\) may not be exactly the same, namely, the distribution of the vertices may not the same in both arrangements. However, they may be similar enough to the point in which one could say they are actually the same. To formalize this, we introduce here several variants of the concept of arrangement isomorphism, each of which defines when two arrangements are similar enough to be the same while the exact distribution of the vertices is not.
Consider, for example, the tree in shown in (a) in the figure below.

Edge isomorphism [7]. The arrangements in (b) are not the same, yet they would overlap perfectly when drawn on top of each other. This motivates the definition of edge isomorphism. Two arrangements \(\pi_1\) and \(\pi_2\) of the same graph are edge-isomorphic if a pair of positions \(p,q\) in \(\pi_1\) are connected by an edge if, and only if, the same pair of positions are also connected by an edge. More formally, two arrangements \(\pi_1\) and \(\pi_2\) of the same \(n\)-vertex graph \(G\) are edge-isomorphic if
\(\forall p,q\) such that \(1<p<q<n\), we have that \(\pi_1^{-1}(p)\pi_1^{-1}(q) \in E \longleftrightarrow \pi_2^{-1}(p)\pi_2^{-1}(q)\) or \(\tilde{\pi_1}^{-1}(p)\tilde{\pi_1}^{-1}(q) \in E \longleftrightarrow \pi_2^{-1}(p)\pi_2^{-1}(q)\)
where, recall, \(\tilde{\pi}\) denotes the mirror of arrangement \(\pi\).
- Level isomorphism [7]. The arrangements in (c) are not the same, and they would not overlap if we drew them on top of each other (as it would happen with the arrangements in (b) ). Nevertheless, both yield the same sum of edge lengths. The reason why is that their level sequences are the same. We say two arrangements \(\pi_1\) and \(\pi_2\) of the same graph are level-isomorphic if their level sequences are the same. More formally, two arrangements \(\pi_1\) and \(\pi_2\) of the same graph \(G\) are level-isomorphic if, and only if, \(L_{\pi_1}(G) = L_{\pi_2}(G)\) or \(L_{\tilde{\pi}_1}(G) = L_{\pi_2}(G)\).
Edge list
An edge list is simply a collection of edges (see Edge).
File with edge list format
A file containing an edge list is a plain text file where each line contains an edge of the graph. Such edge is represented as a pair of non-negative integer values separated by at least one space character. The file may contain blank lines.
These files may be a bit uglier by allowing several edges to be in the same line (the indices must always be separated by at least one space) and even allow new-line characters inbetween the indices of the same edge.
It must be noted that the edges in such a file are the edges of a single graph.
Head vector
Head vectors are a very useful and very well-known representation of rooted trees in which the tree is reduced to a series of \(n\) non-negative integer values. A head vector of an \(n\)-vertex tree is, then, a list of non-negative integer numbers. The number at position \(i\) denotes the parent node of the vertex at said position; value '0' denotes the root. In this case, the vertex corresponding to the value '0' is labelled as the root.
Each tree is formatted as a list of whole, positive numbers (including zero), each representing a node of the tree. The number 0 denotes the root of the tree, and a number at a certain position indicates its parent node. For example, when number 4 is at position 9 it means that node 9 has parent node 4. Therefore, if number 0 is at position 1 it means that node 1 is the root of the tree. A complete example of such a tree's representation is the following
0 3 4 1 6 3
which should be interpreted as
(a) predecessor: 0 3 4 1 6 3 (b) node of the tree: 1 2 3 4 5 6
Note that lines like these are not valid:
(1) 0 2 2 2 2 2 (2) 2 0 0
Line (1) is not valid due to a self-reference in the second position, and (2) is not valid since it contains two '0' (i.e., two roots).
Note that rooted trees (and thus sentences) can be, very naturally, represented using head vectors. This is defined as a type in lal::head_vector.
Centre and centroid of a tree
The concept of "centre" of a tree should never be confused with "centroid" of a tree. The "centre" of a tree are the (at most two) two that result from removing the leaves of a tree all at a time: remove all leaves from the initial tree, remove all leaves from the resulting tree, and so on. The "centroid" should be seen as a centre of masses: these are the (at most two) vertices such that none of their immediate subtrees have more than half of the vertices of the whole tree.
More formally, the "center" is the set of (at most) two vertices that have minimum eccentricity. The "centroid" is the set of (at most) two vertices that have minimum weight, where the weight is the maximum size of the subtrees rooted at that vertex. In both cases, if the set has two vertices then they are adjacent in the tree. See [29] (pages 35-36) for further details.
Diameter of a tree
The diameter is defined as the longest shortest distance between every pair of vertices. The distance is calculated in number of edges; two adjacent vertices are at a distance 1 from each other. See [29] (pages 24, 35) for further details.
The diameter is the length of the longest path. See [29] (pages 24, 35) for further details.
Isomorphism of trees
Decides whether the input trees are isomorphic or not. Two trees \(t_1\) and \(t_2\) (or graphs in general) are isomorphic if there exists a mapping \(\phi \;:\; V(t_1) \longrightarrow V(t_2)\) such that
\(\forall u,v\in V(t_1) \; (u,v)\in E(t_1) \longleftrightarrow (\phi(u),\phi(v))\in E(t_2)\)
and \(\phi(r_1)=r_2\) where \(r_1\) and \(r_2\) are, respectively, the roots of \(t_1\) and \(t_2\). Note that \((u,v)\) denotes a directed edge.
The different types of trees
Here we describe the different types (classes) of trees used in LAL, some of them listed in lal::graphs::tree_type.
- Empty tree (lal::graphs::tree_type::empty). A tree with no vertices at all.
- Singleton tree (lal::graphs::tree_type::singleton). A tree of a single vertex.
- Caterpillar trees (lal::graphs::tree_type::caterpillar). These are the trees such that a linear tree is produced when its leaves are removed [28].
- Linear trees (lal::graphs::tree_type::linear). A linear tree has only two leaves, and the rest of the vertices (if any) have degree exactly two. This is, precisely, a path graph.
- Spider trees (lal::graphs::tree_type::spider). A spider tree has a unique vertex of degree greater than or equal to 3. The other vertices have degree 2 or 1 [13], [37].
- 2-linear trees (lal::graphs::tree_type::two_linear). A 2-linear tree is a tree in which there are at most two vertices of degree 3 or larger; the other vertices have degree 2 or 1 [47], [46]. It can also be seen as the connection of two independent trees \(T_1\) and \(T_2\) where each tree is either a spider tree or a linear tree. If one of \(T_1\) or \(T_2\) is a spider tree, the path must be incident to the spider's hub vertex.
- Star trees (lal::graphs::tree_type::star). Also known as star graphs, trees where all vertices but one have degree 1.
- Quasi-star trees (lal::graphs::tree_type::quasistar). Also quasi star graphs, trees where all vertices but two have degree 1. One of these two vertices has degree exactly two, the other has degree at least two.
- Bi-star trees (lal::graphs::tree_type::bistar). These trees are made of two star trees joined by an edge at their centers.
- unknown tree (lal::graphs::tree_type::unknown). Used when a tree does not fall in any of the categories above.
Linguistics
Treebank
A treebank file is simply a plain text file containing one or more trees represented using their Head vector representation. Each head vector must be written in a single line and each line must contain at most one such vector.
Treebank Collection
A treebank collection is simply a collection (or group) of treebanks (see Treebank) that are related to one another in some way. A really good example is that of the Universal Dependencies treebank: several treebanks of the same language make up a treebank collection that corresponds to some version of UD. Another example would be the collection of treebanks of books of some author. In this setting, each treebank file will contain all the sentences of a single book.
In order to use treebanks with LAL, see classes lal::io::treebank_reader, lal::io::treebank_processor).
Main file of a treebank collection
In order to use treebank collections with LAL (see classes lal::io::treebank_collection_reader, lal::io::treebank_collection_processor), users must make the main file of the collection before.
The main file references all the treebanks in the collection. Its lines contain only two strings, each line describing a treebank. The first string is a self-descriptive name of the treebank (e.g., the ISO code of a language), and the second is the relative path to the file containing the syntactic dependency trees (e.g., the syntactic dependency trees of a language in a collection). The path is relative to the directory that contains the main file.
For example, the main file could be called stanford.txt, representing the Stanford treebank collection, and could contain:
arb path/to/file/ar-all.heads2 eus path/to/file/eu-all.heads2 ben path/to/file/bn-all.heads2 ...
where the first column contains a string referencing the language (in this case, an ISO code), and the second column contains the relative path to the file with the syntactic dependency trees.
Generated by